
5月14日凌晨,OpenAI发布了号称“能够真正理解世界”的端到端多模态AI大模型GPT-4o,成为了整个行业关注的焦点。
然而仅仅过去24个小时,谷歌就通过新版Gemini AI大模型抢回了风头,而且新版Gemini不到两个小时的发布会中,谷歌整整提了121次“AI”。
不难看出,AI正以迅雷不及掩耳之势席卷全球,从PC到手机再到家电,几乎处处可见AI的身影。而结合通义千问、文心一言等国产AI大模型登陆汽车来看,汽车行业无疑是AI大模型的下一个主战场。
新能源汽车的上半场是电动化,下半场则是智能化,未来智驾、智能座舱将成为汽车的核心竞争力,尤其是端到端技术的逐步应用,将智驾推到了新高度。在汽车的智能化进程中,处于行业上游的底层芯片供应商态度极为关键,也会直接影响到汽车智能化时代的发展速度。
正值新能源汽车迈入下半场之际,我们不妨先看看底层芯片供应商的动作,窥探整个行业的发展状态。
智驾篇:端到端时代来临
特斯拉:算力即王道
FSD(完全自动驾驶)技术是特斯拉核心竞争力之一,最近一段时间特斯拉也推出了多次活动,给车主体验FSD的机会。
不少用户反映,进入FSD Beta V12.3版本后,特斯拉汽车智驾给人的感受如同一位老司机,让人有点分不清究竟是不是智驾系统在操作汽车。
按照特斯拉官方的说法,FSD Beta V12.3引入了端到端神经网络,意味着汽车不再是由代码决策和控制,而是神经网络接收信息和输出指令。
硬件方面,特斯拉HW4.0平台针对端到端大模型主要有两大升级,第一是芯片制程工艺升级到了7nm,能够显著降低发热、提升能效,确保芯片可以始终稳定运行。
第二则是算力提升,为HW3.0的5倍。端到端大模型取消了强规则、不依赖高精度地图,但是对于算力的需求非常高。HW4.0将AI算力从上一代的144TOPS升级至720TOPS,为端到端大模型提供了有力的算力基础。
最后,HW4.0的摄像头像素也得到了升级,从120万提升至500万像素。不过目前绝大多数运行特斯拉FSD Beta V12.3的车辆,主要是过去交付的基于HW3.5平台的产品,说明特斯拉的算法的确厉害,在144TOPS算力的平台上也有极为出色的表现。
NVIDIA:要做就做最强
在皮衣刀客黄仁勋眼中,汽车行业是NVIDIA营收和利润突破的一次契机,但从财报数据来看,去年第四季度营收仅2.81亿美元的汽车业务对NVIDIA影响微乎其微。
不过情况很可能就要发生改变了,过去NVIDIA被车企大规模采购的Orin系列智驾芯片虽强,却没有与其他厂商的芯片拉开绝对差距,而明年全球将有多家车企为旗舰产品配备目前行业AI算力最高的芯片“NVIDIA DRIVE Thor”。

北京车展上,NVIDIA展示了Thor芯片和端到端人工智能技术,NVIDIA DRIVE是其打造的汽车自动驾驶开发和部署端到端平台,能够根据传感器数据构建3D场景,并通过Neural Recinstruction Engine引擎重建完整的3D数字孪生,开发者甚至可以通过采集到的场景和素材创作场景,用于大模型训练。
DRIVE Thor的AI算力高达2000TOPS,目的就是为端到端智驾提供算力支持,但面对黑盒问题和算力上可能存在的挑战,NVIDIA表示还要通过在端到端模型中加入观测点、投资数据中心和训练工具,提高芯片计算能力和安全性。

另外,DRIVE Thor不仅仅支持自动驾驶计算,还支持智能座舱运算,是一颗具备“驾舱融合”能力的芯片。
近几年已有不少车企和芯片厂商考虑驾舱融合,他们的想法是智能座舱芯片可以为智驾提供算力冗余,以提高智驾功能的安全性,智驾芯片也可以将算力共享给智能座舱,增强智能座舱的娱乐能力。
北京车展上,NVIDIA官方表示,目前芯片更多是基于通用GPU,但公司会不断调整,优化硬件架构,实现AI硬件的快速迭代。
地平线:硬件厂商也要做算法
作为国内头部智驾芯片厂商,地平线公司的征程3、征程5芯片已广泛应用在理想、长安、东风、广汽等车企的车型上。北京车展上,地平线也带来了最新一代产品征程6系列,分为B/L/E/M/H/P六个版本,算力从数十TOPS到数百TOPS不等。
结合征程6系列芯片,地平线推出了SuperDrive高阶智驾方案,基于端到端和数据驱动技术,实现了城区NOA。SuperDrive通过Transformer架构 将动态、静态、OCC(Occupancy占用网络)三网合一,能够有效解决当前智驾技术普遍存在的感知架构时延高、规则多、负载重等问题。
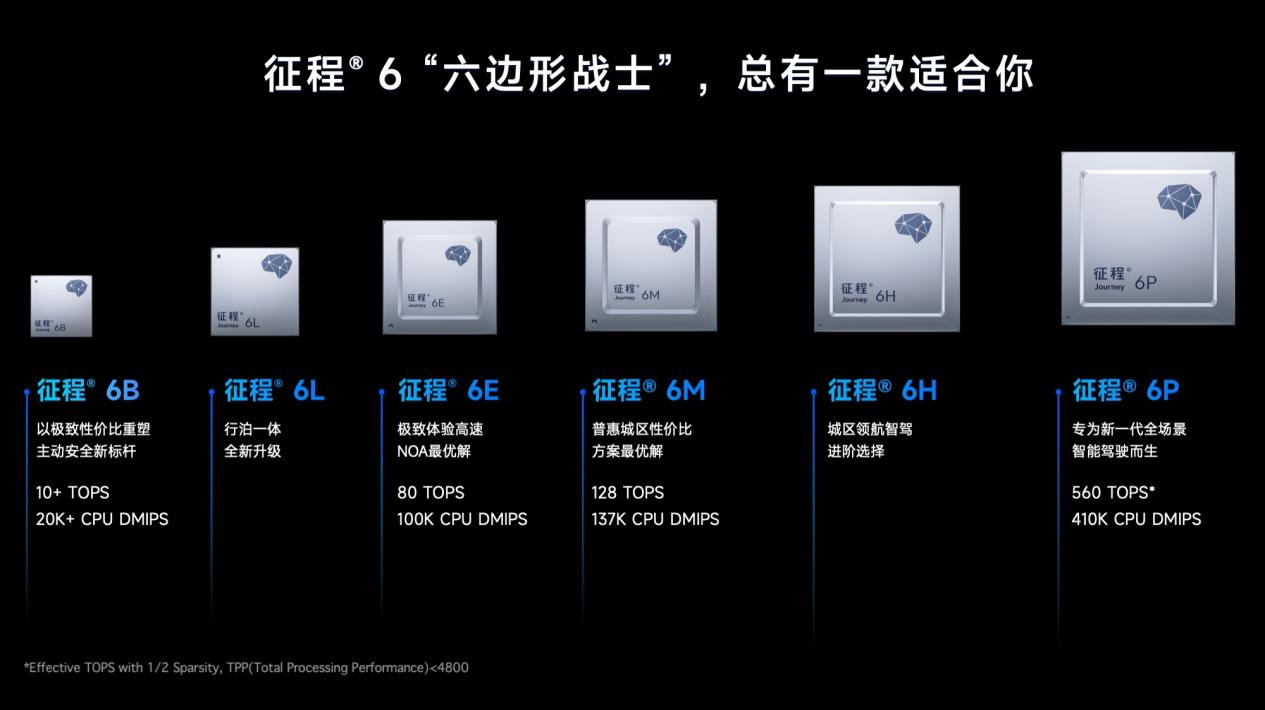
另外,地平线智能驾驶产品规划与市场总经理吕鹏曾表示,征程6芯片专门针对AI运算进行了架构设计和调整,例如支持多线程并发的SIMT Vector Processing Unit(VPU)和BF16/FP16/FP32多种浮点数据类型,能够更好地平衡运算性能和精度;支持Layer-norm&Softmax和Transpose&Reshape算子的硬件加速,能够大幅减少运算时间。
地平线应该是世界范围内为数不多针对AI运算做架构、算法优化的智驾芯片供应商,这多和他们自己有配套的智驾解决方案有关。客观来说,这种做法在未来可能会变得更加主流,因为专属硬件优化拥有更好的开发效率和实际效果,这放在谈判桌上会是不错的筹码。
黑芝麻:行泊一体与驾舱融合齐头并进
还是在上个月的北京车展上,黑芝麻智能公布了旗下武当、华山两大智驾芯片产品线的最新动向,其中武当系列C1236、C1296两款芯片登场。C1236属于行泊一体芯片,支持NOA功能,C1296则属于驾舱一体芯片,并且内置安全隔离MPU,以满足低成本驾、舱、泊融合需求。

另外,这两款芯片还搭载黑芝麻智能自研核心IP,通过高性能ISP和NPU,为摄像头传感器和AI计算技术框架提供支持。
黑芝麻智能还发布了面向新一代自动驾驶算法的第三代DynamAI NN引擎,新一代NPU不但原生支持Transformer,可为端到端算法提供保障,还通过升级后的存取架构设计,能够降低车企开发自动驾驶技术的便捷性,降低智驾平台在DDR方面的投入。
黑芝麻智能在国内市场存在感不如地平线,武当和华山两大系列芯片的算力与头部企业也有差距。武当系列两款芯片的到来,能够看出黑芝麻智能希望改变现有局面,但第三代自动驾驶算法DynamAI NN引擎能否帮助黑芝麻弯道超车,依然要等待市场检验。
小结:端到端时代,硬件厂商依然狂卷算力
结合这些企业的动作来看,底层芯片厂商大多没有针对端到端进行太多优化适配,主要动作依然是在传统架构下,优化制程工艺、提升AI算力。
其中的主要原因或许在于算法的升级迭代速度远超硬件,如今天国内车企普遍使用的智驾芯片NVIDIA DRIVE Orin发布于2019年,地平线旗下的征程5芯片发布于2021年。而在今年5月20日的520 AI Day上,何小鹏透露端到端大模型2天即可迭代一次,18个月智驾能力能够提升30倍。
在AI计算中,专用AI芯片相较于通用芯片几乎是碾压式领先,若能基于端到端大模型优化和设计芯片,必然能够推动端到端技术的进步,加速端到端大模型研发和实现。尤其是在端到端大模型存在黑盒问题的今天,更加需要专业性芯片为智驾安全保驾护航。
底层芯片厂商迟迟没有推出针对端到端大模型设计的芯片,核心因素在于端到端大模型真正爆火,其实是特斯拉FSD Beta V12.3版本的到来。端到端大模型仍处于落地早起阶段,对于行业上游的底层硬件厂商还没有起到深刻影响。
因此,针对端到端大模型优化和专门开发的芯片,可能要等到下个周期才会出现。按照智驾芯片迭代升级的速度,预计2026年前后,此类芯片才会面世。
反而是智能座舱方面,底层硬件厂商更注重AI大模型,并且急于实现生成式AI上车。
智能座舱篇:端侧大模型时代到来
高通:从AI大模型到驾舱融合
手机行业赫赫有名的高通,进军智能座舱芯片市场后推出了高通8155/8295等深受车企和消费者认可的芯片。
在AI大模型登陆汽车的关键时刻,高通迅速作出反应,其推出的高通8295芯片不但拥有超过最高60TOPS AI算力,而且首次采用双NPU架构。智能座舱芯片的AI大模型运算依赖NPU,双NPU可以有效提升大模型运算的速度和性能,虽然可能会带来一定的能耗提升,但对于汽车平台而言影响不大。
就目前的体验来看,汽车领域AI大模型发挥的作用主要在让车机系统和语音助手更加智能,部分汽车还加入了对生成式AI的支持,用户可以使用生成式AI创作文字、图片、音频等内容,例如极越汽车就将百度文心一言大语言模型引入了车机。

面对NVIDIA、黑芝麻等智驾芯片厂商发布驾舱一体芯片的举动,高通也予以回击。北京车展上多家企业展示了基于高通芯片开发的驾舱融合产品,例如车联天下的AL-A1产品,基于高通SA8775P驾舱融合平台打造,不但可以部署端侧AI大模型,为用户提供完善的整车智能体验,还支持L2级辅助驾驶,高速NOA、城区记忆行车等功能。
端侧AI大模型能够结合用户的使用习惯建立大模型,提供更符合个人需求的智能化体验,而且还能避免信息的反复传输,有利于保护用户隐私,已然成为当前PC、手机、汽车等领域的发展趋势。
联发科:打造极致AI大模型
早在2016年就布局车机芯片的联发科,前段时间发布了全新一代智能座舱平台CT-X1,并在业内引发了轩然大波。
CT-X1基于3nm制程工艺,支持130亿参数端侧大模型,可以同时在车内运行主流大语言模型(LLMs)和AI绘图功能(Stable Diffusion)。此外,该平台还具有联发科专为生成式AI设计的AI运算单元,硬件层面支持Transformer子运算加速,能够提升AI大模型和生成式AI的运算效率,实现更精准的人机交互。

联发科还引入了混合精度量化技术和内存硬件压缩技术,进一步提高AI大模型的生成速度,降低AI大模型对于内存带宽和容量的要求。在CT-X1的加持下,汽车能够更精准地理解车内乘客的语言、动作、表情,并给出相应的回馈。
另外,为了加速汽车端AI大模型和生成式AI落地和完善体验,联发科还与超过25家生成式AI合作伙伴联手,针对智能座舱打造出了丰富的生成式AI使用场景。整体而言,联发科全新的座舱芯片平台很有机会从高通手中抢过“王冠”,成为性能指标上的新王者。
不过客观来说,联发科的芯片平台知名度还有待提升,也需要和更多的合作伙伴展开合作、上车更多车型,而针对AI大模型的“重点部署”,有机会成为突破口。
AMD:让车机更像电脑
今年初的CES国际消费电子展上,AMD带来了Versal AI Edge XA自适应式系统集成芯片和Ryzen嵌入式V2000A系列处理器,其中Versal AI Edge引入了AI引擎,优化了汽车系统和应用,包括各类传感器、自动泊车、自动驾驶。
V2000A系列则是AMD专为下一代智能座舱设计的芯片,而且还扩展了符合x86架构的处理器系列,能够提供类似PC的体验,并支持Linux和Android Automotive操作系统。

作为全球知名的PC硬件厂商,AMD在GPU领域AI计算方面就落后NVIDIA,如今进入汽车行业后,所推出的产品虽然针对AI计算进行了优化,但并没有太多AI大模型的针对性设计和优化。
从中能够看出底层芯片厂商之间的差距,高通、联发科深耕中国市场,对于国内消费者的要求较为了解。AMD的车载硬件国内罕有车企使用,对于中国市场的耕耘不够深入,因而未能像高通、联发科一样不但硬件专门适配AI大模型,还要与开发者合作帮助AI大模型上车。
亿咖通:它山之石可以攻玉
2021年12月10日,武汉芯擎科技正式发布了龙鹰一号智能座舱芯片,该芯片基于7nm制程工艺,拥有88亿颗晶体管,AI算力为16TOPS,于2023年3月30日官宣量产。
龙鹰一号对标高通8155芯片,搭载两颗龙鹰一号的领克08 EM-P曾获得2023年车机流畅榜第一名。不过面对新时代AI大模型的到来,亿咖通认识到龙鹰一号的制程工艺和算力均有所不足。于是,亿咖通最强计算平台乔戈里选择了高通骁龙8 Gen 3芯片。
骁龙8 Gen 3是高通为旗舰手机设计的高端芯片,基于4nm制程工艺,具有60TOPS AI算力且支持100亿参数端侧AI大模型,全新的Hexagon NPU性能提升98%,能效提升40%,CPU和GPU性能更是大幅领先其他车机芯片。
亿咖通将基于乔戈里平台部署端侧AI大模型和生成式AI,全面升级智能座舱的AI能力。另外,亿咖通还与百度达成合作,将文心大模型搬上了汽车。
与其他底层硬件厂商相比,亿咖通和芯擎科技的实力略显薄弱,但能够将骁龙8 Gen 3带上汽车,融入自己的乔戈里平台,也能说明亿咖通对于智能座舱平台的研发有独到之处。
值得一提的是,亿咖通所有平台的命名均为地球上的山峰,其中乔戈里为地球第二高峰,似乎预示着未来将推出性能和AI算力更强的平台。
小结:探索各不相同
严格来说,这三家芯片厂商的方向各不相同,高通引入AI大模型的同时,更注重驾舱融合,向自动驾驶领域发展;联发科则致力于AI大模型和生成式AI上车,为车内乘客提供更完善的智能座舱体验;AMD或许是因为PC行业出身,更看重软件生态。
很大程度上这些芯片厂商所做的还是在发挥自己的长项,比如联发科和高通还会提供自己在通讯方面的技术积累,而且在图像显示方面也有一定的优势。但在市场竞争的驱动下,或许座舱芯片的发展方向始终会“殊途同归”,出现性能强大的综合性芯片。
面对NVIDIA、黑芝麻智能灯企业发起的驾舱融合挑战,座舱芯片企业也需要考虑布局自动驾驶,以免在驾舱融合时代到来的时候掉队。当然,驾舱融合并不代表一家企业要做所有事情,如联发科就选择与NVIDIA合作,充分发挥双方优势,开发驾舱融合方案。
总结:汽车行业大势已现
大约2020年前后,汽车行业真正进入智能时代,到目前为止,整个行业对于智能汽车仍处于探索阶段。汽车智驾芯片、座舱芯片的更新频率较低,底层芯片厂商的一举一动,都是行业发展方向的体现,会影响未来数年行业格局。通过这些底层芯片企业的动作不难看出,端到端、驾舱融合、AI大模型已成为行业趋势。
其中端到端代表着整个汽车行业智驾方向的转变,该技术将改变整个汽车行业的智驾格局,但其黑盒特性导致安全性短期仍需要重点关注,甚至未来数年内,仍需要强规则干预,防止大模型出现问题。

驾舱融合已经走到了关键节点,NVIDIA、黑芝麻智能、高通等企业,纷纷推出了支持驾舱融合的芯片,而且2025年开始,全球将有多家车企为产品配备NVIDIA DRIVE Thor芯片,明年或许可以成为汽车行业驾舱融合元年。
至于AI大模型和生成式AI,尽管已有不少车型支持,但对于车内乘客的体验提升较为有限。原因或许在于整个行业对大模型和生成式AI的发掘较为浅显,尤其是应用到汽车端后,除了人机交互更智能、能够生成一些图片、文字和回答问题,并没有给用户带来过于明显的体验提升。
我们不能对一个刚诞生的婴儿提出太多要求,小通相信,随着算力的提升、技术的进步,以及行业对于AI大模型和生成式AI探索的加深,未来车企和开发者将赋予AI大模型和生成式AI更丰富的玩法与无限的可能性。
车企和芯片厂商对于智能、智驾的探索,最终会惠及每一位消费者,我们也期待未来有一天,车企能够带给我们像《回到未来》《三体》等作品中充满科幻感的产品。
来源:雷科技
原文标题 : AI大模型兵临车圈城下:智驾芯片堆算力,座舱芯片寻出路






